
With years of experience using the industry-standard power curve modelling approach, Clir identified several shortcomings that result in poor turbine power curves estimates and uncertainty. In particular, the industry approach is sensitive to mislabeled training data and small data sets, which impact the accuracy and robustness of any analytics that use these models.
That’s why we’ve developed a new, AI-based methodology to power curve modelling. Using past observations and a machine learning approach for regression called Gaussian process (GP), this methodology addresses several shortcomings of the standard approach. It also enables a scalable, automated solution for identifying accurate probabilistic power curve models which supports increased automation and improved confidence in results or analytics.
Power curve utility
Turbine power curves — and by extension, power curve modelling — enable a core feature of the Clir app: wind turbine potential energy production estimates. By analyzing observed wind speeds, we can identify moments where the wind turbine was not operating at full production, the difference between potential and true energy production, and estimated lost energy.
Another application of historical power curves is anomaly detection, conditioned on the observed wind speed, power and other variables. At Clir, we maintain a collection of wind turbine performance algorithms that identify and classify wind turbine under-performance events that may not be identified by the OEM event data, such as icing, derating and unexplained outages. Anomaly detection relies on historical models to describe the uncertainty in each individual power curve. When power performance sufficiently deviates from expected performance, it is classified as anomalous. In order for these detection algorithms to function accurately, there must be accurate turbine power curve uncertainty models.
The Clir approach
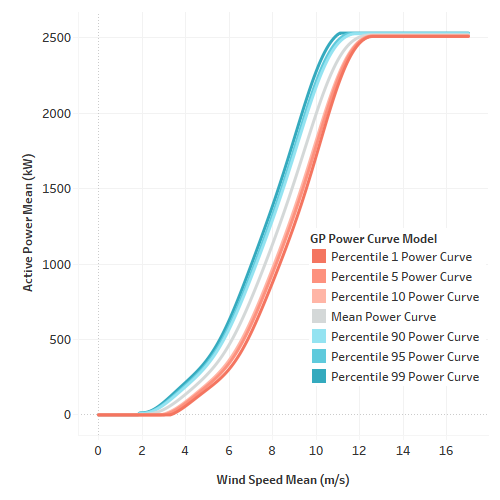
Although the GP approach does work with a higher proportion of mislabeled data, when compared to the traditional approach, Clir has access to high-quality and well-labelled data. This means that the training data sets are cleaned and periods of underperformance are to be discarded. The Gaussian process generates probabilistic predictions of variables to provide a mean predicted value and the associated uncertainty. Combining these values, Clir can infer accurate power curves.
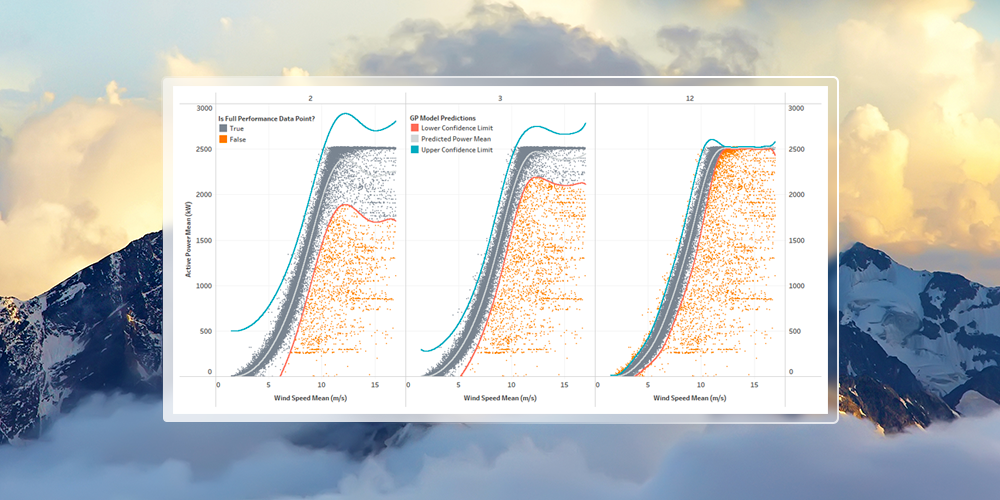
This is combined with a recursive model fitting process that identifies underperformance in the training data. During each iteration of the recursive model fitting process, the fitted power curve model produces confidence intervals that can be used to identify and discard outlier data. After each iteration, the training data should better represent full turbine performance.
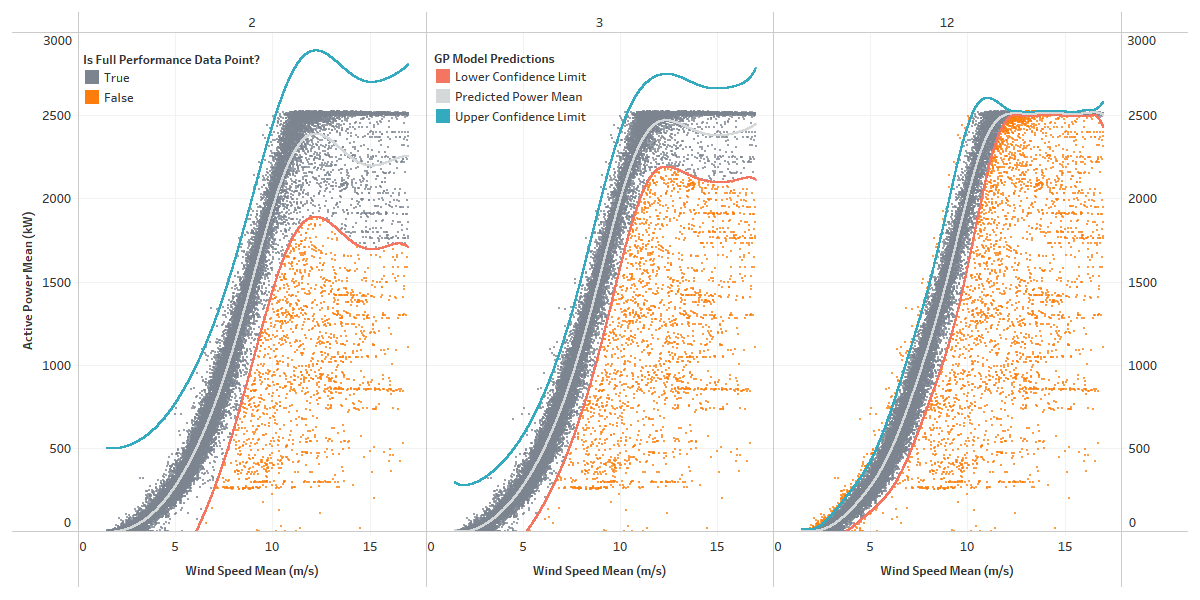
Using Clir’s methodology
A more accurate power curve modelling approach enables a range of new capabilities and opportunities. Using the GP, we are able to identify performance anomalies and attribute a cause. We’re also able to provide:
-
Better estimates of potential energy values.
-
Accurate and robust quantification of power curve uncertainty.
-
More robust handling of mislabelled training data.
If you’re interested in learning more about our approach, contact us.






